PPT: Pre-trained Prompt Tuning for Few-shot Learning
针对小样本学习的预训练提示调优
abstract
- 通过弥合预训练任务和各种下游任务之间的差距,预训练语言模型 (PLM) 的提示显示出卓越的性能。
- 当下游数据充足时,即时调整的性能与传统的全模型微调相当,而在少样本学习设置下它的表现要差得多,这可能会阻碍即时调整在实践中的应用。这种低性能是因为初始化软提示的方式。
- 本文通过在预训练阶段添加软提示来预训练提示以获得更好的初始化,并将此预训练提示调优框架命名为“PPT”。
- 为了保证PPT的泛化性,作者将相似的分类任务制定成统一的任务形式,并为这个统一的任务预训练软提示。
1 Introduction
两种主流的FT方法:
- 面向任务的微调,在 PLM 之上添加一个特定于任务的头,然后通过优化在特定任务训练数据的特定任务学习目标来微调整个模型。
- 面向提示的微调,将数据样本转换为包含提示标记的线性化序列,并将所有下游任务形式化为语言建模问题。 与面向任务的微调相比,面向提示的微调在目标(掩码语言建模)方面更类似于预训练,从而有助于更好地利用 PLM 中的知识并经常获得更好的性能。
提示调整 (PT) :
PT 使用由连续嵌入组成的软提示而不是硬提示(离散语言短语)。 这些连续提示嵌入通常是随机初始化和端到端学习的。 为了避免为每个下游任务存储整个模型,PT 冻结 PLM 的所有参数,仅调整软提示,而不添加任何中间层和特定于任务的组件。
本文广泛探索了如何通过 PT 以高效和有效的方式使用 PLM 进行小样本学习。
为了帮助模型找到合适的提示,我们在大规模未标记语料库上使用自监督任务预训练这些标记。为了确保预训练提示的泛化,我们将典型的分类任务分为三种格式:句子对分类、多项选择分类和单文本分类,每种格式对应一个自监督的预训练任务。此外,我们发现多选分类在这些格式中更为普遍,我们可以将所有下游分类任务统一为这种格式。我们将此预训练提示调优 (PPT) 框架命名为“PPT”。
2 pilot experiments
本节在少样本设置下展示 PT 的几个试点实验。 作者凭经验分析了三种主要类别的提示增强策略的有效性,包括混合提示调整、语言表达选择和实词初始化。
(1) Hybrid Prompt Tuning
在混合提示调整中,软提示标记和硬提示标记都被使用。 然而,以前的工作与整个模型一起训练软提示。 在 PT 的情况下,只有提示令牌是可调的,使用混合提示的有效性尚未得到充分探索。 此外,不同的硬模板对性能影响很大,需要大量人工进行提示设计和选择,为下一次调优提供了潜在的初始化。
(2) Verbalizer Selection
如何选择将特定任务标签映射到具体标记的语言器也值得研究。 不同的语言表达器选择对性能影响很大。 通常,解释相应标签含义的常用词效果很好。
(3) Real Word Initialization
对于具有 11B 参数的模型, 实词初始化对少镜头设置下的性能影响很小甚至是负面影响。 这表明对小模型的观察不能直接转移到大模型,并且为软提示标记找到一个好的初始化仍然至关重要。
3 pre-trained prompt tuning(PPT)
3.1 Overview
遵循 T5 和 PT 的方法,我们以文本到文本的格式解决所有下游任务。为了缩小预训练和下游任务之间的目标差距,prompt-oriented 微调将下游任务转换为一些完形填空式的目标。
以分类任务为例:
给定输入句子 $x ∈ \mathcal{V}^∗$ 及其标签 $y ∈\mathcal{ Y}$,首先应用模式映射$ f :\mathcal{ V}^∗→ \mathcal{V}^∗ $将 x 转换为新的标记序列 f(x), 其中 $ \mathcal{V}$ 是 PLM 的词汇表。 f(x) 不仅添加了一些提示标记作为提示,而且还保留了至少一个屏蔽token $<\mathbf{X}>$ 以让 PLM 预测屏蔽位置处的标记。 然后,使用语言表达器$ v :\mathcal{ y}→ \mathcal{V}^∗ $ 将 y 映射到标签token序列 v(y)。 使用 f(·) 和 v(·),分类任务可以用模式-语言表达器对 (f, v) 表示:
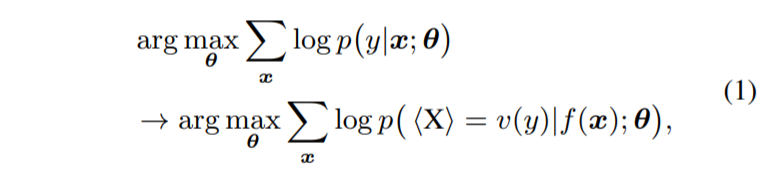
其中 θ 表示所有可调参数。使用“PVP”来表示这个模式-言语者(verbalizer)对。
在 PT 中,一组软提示标记 P 连接到序列的前面,模型输入变为 [P ; f(x)],其中 [·; ·] 是连接函数。 通过在固定其他参数的情况下单独调整 P,方程(1) 被替换为:
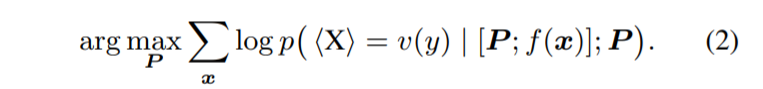
最近,预训练已被证明是找到一个好的模型初始化的有效方法。 受此启发,我们建议对软提示进行预训练。 由 NSP 预训练的软提示可以很好地初始化这些句子对任务。
形式上,将下游任务分成 m 个组 ${\mathcal{T}1,\mathcal{ T}_2, …,\mathcal{ T}_m}$,其中$\mathcal{ T}_i$ 是包含 $n_i$ 个下游任务的集合:${PVP^1_i ,PVP^2_i , …, PVP^{n_i} i }$,其中 $PVP^k_i = (f^k_i , v^k_ i )$。 对于每一组,我们设计一个相应的预训练任务 $PVP^{pre}_ i = (f^{pre}_ i , v ^{pre}_ i )$。 在所有模型参数固定的这些预训练任务上预训练软提示后,我们得到 m 个预训练提示 ${P_1, P_2, …, P_m}$。 预训练后,对于 $\mathcal{T}i$ 中的每个任务 $PVP^k i$,我们继续优化方程(2)通过使用$P_i$作为软提示的初始化。
3.2 Designing Pattern-Verbalizer Pairs for Pre-training
3.2.1 Sentence-Pair Classification
| 以两个句子$ x = (s1, s2)$ ,将标签 $\mathcal{Y} = [0, 1, 2]$ 的 3 类分类作为预训练任务。 Y中的这些标签可以分别表示两个句子之间的语义关系是连贯的、相似的和不相关的。 为了从未标记的纯文本文档中构造信号,我们将相邻的两个句子设为标签 2,来自同一文档但不相邻的设为 1,来自不同文档的设为 0。我们考虑标签集 $ | \mathcal{Y} | <= 3$, 因为这涵盖了大多数句子对任务。 $PVP^{pre}_ i = (f^{ pre}_ i , v^{pre}_i )$ 给出如下: |
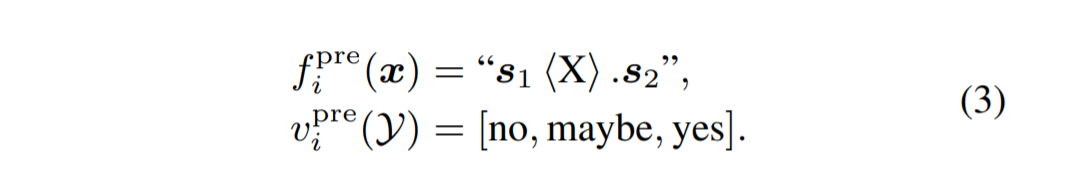
根据 $PVP^{pre}_ i$ 设计 $PVP^k_ i = (f^ k_ i , v^k i )$ 很简单。 $s_1$ 和 $s_2$ 可以用输入句对代替。 如果一个任务输出两个标签,那么我们取$ v^ k i (\mathcal{Y}) = [no, yes]$。 如果一个任务输出三个标签,我们设置 $v^ k_ i = v^{pre}_ i$ 。 如果一个任务需要测量两个句子之间的相似度,{no, yes} 的概率可以用于这个任务。
3.2.2 Multiple-Choice Classification
许多任务可以表述为多项选择分类,它以一个查询和几个候选答案作为输入。
我们设计了一个下一句选择任务来预训练提示。 给定一个句子作为查询 $s_q$,模型被训练从六个候选中选择相邻的句子,表示为 $s_1 ∼ s_6$,因此标签集是 $\mathcal{Y} = [1, 2, 3, 4, 5, 6]$。 这些候选包括正确答案、来自同一文档但不与查询相邻的一个句子以及来自其他文档的四个句子。 对于 $x = (s_q, s_1, s_2, · · · , s_6), (f ^{pre}_ i , v ^{pre}_ i )$ 给出为:
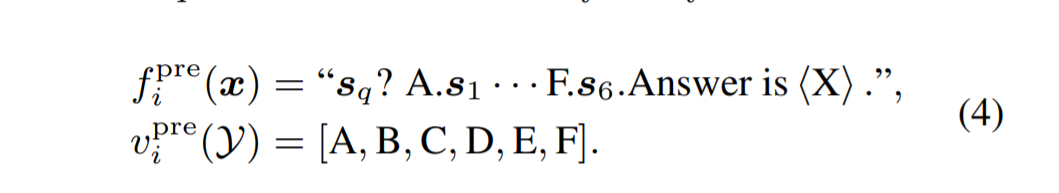
大多数多项选择任务可以直接使用${f ^{pre}_i , v ^{pre} _i }$ 作为它们的 PVP。 对于阅读理解等任务,输入可能包含一段话和一个问题。 我们将它们连接起来形成一个查询。
3.2.3 Single-Sentence Classification
对于单句分类,我们为提示预训练创建了伪标签。 以情感分类为例,我们使用另一个小模型对来自预训练语料库的句子进行情感标签标注,过滤掉分类概率较低的句子。 在实践中,我们使用 RoBERTaBASE 模型在 5 类情感分类数据集上进行了微调,而不是我们测试的小样本数据集。 然后使用语料库中的句子 $s$,我们有输入 $x = (s) $和标签集 $\mathcal{Y} = [1, 2, 3, 4, 5]$。 $(f^{pre} _i , v ^{pre} _i )$ 给出为:
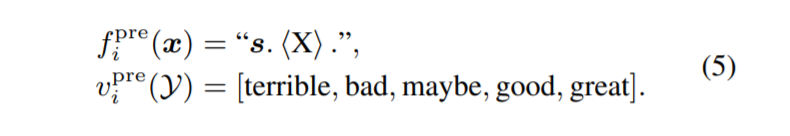
对于有 5 个标签的情感分类任务,我们可以使用 $PVP^k_ i = PVP^{pre}_ i$ 。 对于那些标签少于 5 个的任务,我们从 $v ^{pre}_ i (\mathcal{Y})$ 中选择一个子集作为标签。
3.3 Unifying Task Formats
上述用于预训练的 PVP 可以统一为一个格式:多选分类。 具体来说,对于句子对分类任务,查询是两个句子的连接,有三个选项:no、maybe 和 yes。 对于单句分类,查询是输入的句子,选项是具体的标签。
4 Experiments
4.1 Setup
-
对中文和英文任务进行了实验。对于少于 5 个标签的任务,我们使用来自原始训练数据的 32 个样本构建训练和验证集,并确保标签数量平衡。对于 超过 5 个标签的任务,为每个标签随机选择 8 个样本。
-
对于英语数据集,我们使用具有 11B 个参数的 T5-XXL 作为我们的基础模型来进行 PT。对于中文数据集,我们基于 CPM-2 进行 PT。由于 CPM-2 不提供其他尺寸的模型,我们将其与各种尺寸的 mT5进行比较。
-
我们始终为 PT 使用 100 个软令牌。结果,可调参数只有 100×4096 = 4.1 × 10^6 = 410K。与 FT 的 11B(1.1×10^10)参数相比,PT 只需要为每个任务存储 3000 倍小的参数。
4.2 Main Results
Effectiveness
- 随着参数数量的增加,FT的性能有所提升。 这意味着大规模模型仍然有助于小样本学习。
- PPT 在大多数数据集中明显优于 Vanilla PT 和 LM Adaption。
- PPT 在所有中文数据集和大多数英文数据集上的 10B 模型上优于 FT。 这表明掩码语言建模和下游任务之间仍然存在差距。
- PPT 在大多数数据集上导致较低的方差。 在预训练的帮助下,所有数据集的方差都保持在较低水平。
5 Conclusion
本文介绍了 PPT,这是一个改进小样本学习的快速调整的框架。 我们建议首先将下游任务统一为多种格式。 然后,我们为每种格式设计自我监督的预训练任务,并对这些任务的提示进行预训练。 最后,我们根据相应预训练提示的初始化对下游任务进行提示调整。 大量实验表明,我们的方法明显优于其他即时调整基线,性能与全模型调整相当甚至更好。
未来的工作有两个重要方向:(1)为其他类型的任务(如语言生成和关系提取)设计统一的任务格式和相应的预训练目标。 (2) 除软提示外,统一任务预训练是否有助于预训练语言模型本身。