NSP-BERT: A Prompt-based Zero-Shot Learner Through an Original Pre-training Task —— Next Sentence Prediction
NSP-BERT:通过原始预训练任务的基于提示的零样本学习器——下一句预测
1 Introduction
论文主要贡献:
- NSP-BERT 在不使用任何特定任务的训练数据的情况下,在零样本模型中实现了 SOTA 性能。
- 提出了两种替代的label/answer mapping方法。
- 使用软定位和两阶段提示构建方法来缓解基于句子级提示的模型对标记位置不敏感的问题。
- 证明了一个简单的基于交互模型的句子级对比学习预训练任务可以很好地适应基于提示的学习并解决各种 NLP 任务。
2 Related Work
一些关于zero-shot 和few-shot的prompt-learning的模型和任务。
-
MLM/L2R LM:token-level prompt-learning methods。
- Sentence-Level Prompt-Learning **:EFL**将 NLP 任务重新表述为 sentence entailment-style tasks。输入/标签对:”x: [CLS] The Italian team won the European Cup. [SEP] This is Sports news.[EOS], y: Entail”。 EFL 模型可以在少样本学习上表现良好,但在零样本任务上表现不佳。
- Automated Prompt:自动搜索,生成提示。LMBFF模型使用条件似然自动选择标签词,并使用 T5 生成模板。 AUTOPROMPT **使用梯度引导搜索来创建提示。 与上述离散提示搜索方法相比,P-tuning** 采用可训练的连续提示嵌入,通过 P-tuning,GPT 在监督学习中实现了与类似大小的 BERT 相当甚至更好的性能。
- optimization methods in prompt-learning:ADAPET通过在完整的原始输入上分离label token的损失和label-conditioned的 MLM 目标来使用更多的supervision。 PTR结合了逻辑规则,用几个简单的子提示来组成特定于任务的提示。指出 GPT 中存在 3 种类型的偏差(多数标签偏差、新近偏差和普通标记偏差)。 通过使用无内容输入(例如“N/A”)来校准模型的输出概率,GPT-2 和 GPT-3 的性能得到了显着提高。
3 Framework of NSP-BERT NSP-BERT
3.1 Next Sentence Prediction
NSP ——BERT模型的两个基本预训练任务之一,同时将两个句子 A 和 B 输入到 BERT 中,以预测句子 B 是否在同一文档中的句子 A 之后。 在特定训练中,有 50% 的时间,B 是 A 之后的实际下一个句子(IsNext),另外 50% 的时间,作者使用语料库中的随机句子(NotNext)。
(1) 等式
\[q_M(n_k|X_i)=\frac{\exp{s(n_k|x_i^{(1)},x_i^{(2)})}}{\sum_{n}{\exp{s(n|x_i^{(1)},x_i^{(2)})}}}\]- $M$表示在大规模语料库上训练的模型。
- $X_i{(1)}$ 和 $X_i{(2)}$ 分别表示句子 A 和句子 B。 模型的输入是 $X_{input}$,$q_M$ 表示模型的 NSP 头部的输出概率。
- $s = W_{nsp}h_{[CLS]}$,其中 $h_{[CLS]}$ 是 [CLS] 的隐藏向量,$W_{nsp}$ 是 NSP 任务学习的矩阵,$W_{nsp} ∈ R^{2×H}$。
-
NSP 任务的损失函数 $L_{NSP} = − logq_M(n x)$ ,其中 $n ∈ {IsNext, NotNext}$。
(2) NSP任务不是确定两个短语的顺序,而是确定他们是否具有相同的主题
(3) NSP任务与对比学习任务非常相似具有逻辑推理能力:
- NSP任务是interactive的,token不仅可以与本句子中的其他token交互,也可以和别的句子的token交互。
- NSP 任务与 MLM 任务一起训练。 MLM任务为整个模型的self-attention机制提供了训练基础。
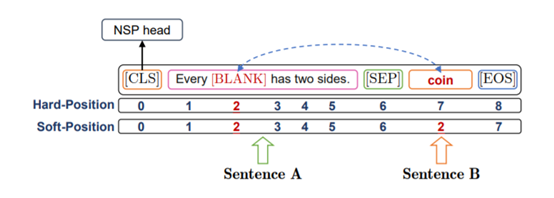
3.2 Prompts in NSP-BERT
NSP-BERT 与其他基于提示的学习方法一样,需要为各种任务构建合适的模板。 由于 NSP-BERT 不依赖任何下游任务的训练数据,因此模板的构建形式必须与原始 NSP 任务紧密匹配。 本节展示如何为不同的任务构建模板。
(1) Single Sentence Task
样本必须在单句任务中分类为不同的主题,比如情感分析是将文本分类为各种感情趋势。
假设单句分类任务的训练数据集D: \(D = \{(x_i,y_i)\}_{i=1}^{N}\) $x_i$ 是总共 N 个样本中的第 i 个句子,$x_i$ 的标签为 $y_i$ ,可以映射到 $y ^{(j)} ∈ Y$,其中 $|Y| = M$,M 是这个数据集中的主题数。 对于每个 $y^{(j)} $,它将被映射到一个模板 $p^{(j)} ∈ P$。模型的输入将是: \(X_{input} = [CLS]x_i[SEP]p^{(j)}[EOS]\) 样本$x_i$的标签为$y^{(j)}$的概率: \(q(y^{j}|x_i) = \frac{\exp{q_M(n=IsNext|x_i,p^{(j)})}}{\sum_{p^{(k)}∈P}{\exp{q_M(n=IsNext|x_i,p^{(k)})}}}\)
(2) Sentence Pair Task
句子对任务旨在识别两个句子之间的关系,这种类型的数据集$D={(x_i^{(1)},x_i^{(2)},y_i}_{i=1}^N$包含 N 个样本,每个样本有 2 个句子 $x _i^{(1)} $ 和$ x _i^{(2)} $。 它们之间的关系是 $y^i $,可以映射到 $y ^{(j)} ∈ Y$,其中$|Y| = M$,是关系类型的数量。NSP模型的输出为: \(q(x_i)=q_M(n=IsNext|x_i^{(1)},x_i^{(2)})\)
(3) Cloze-Style Task
完形填空式任务是给出一个带有空格的句子,模型必须找到最合适的token或span来填充空格。
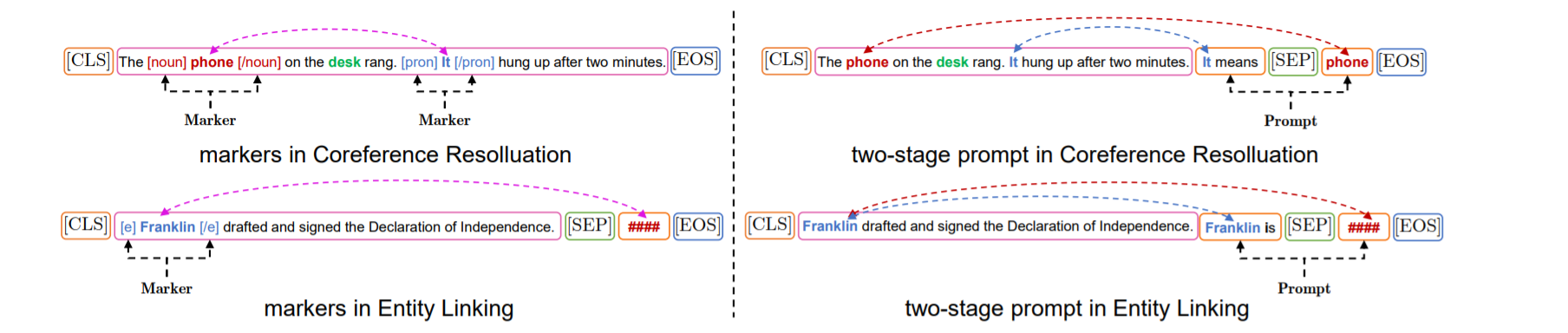
数据集$ D = {(x_i , c i^{(1)} , …, c _i^{(j)} , …, y_i)}{i=1}^N$。对于每个样本,有一个 [BLANK] 的句子$ x_i$,并且有 $K_i $候选 ${c i^{(j)} }{j=1}^{K_i} $可供选择。 对于每个选项$c_i^{(j)}$,都有一个模板 $p _i^{(j) } ∈ P_i$ 与之对应。 对于输入:
\(X_{input}=[CLS]x_i[SEP]p_i^{(j)}[EOS]\)
输出模型:
\(q(y_i^{(j)}|x_i)=\frac{\exp{q_M(n=IsNext|x_i,p_i^{(j)})}}{\sum{p_i^{(k)∈P_i}\exp{q_M(n=IsNext|x_i,p_i^{(k)})}}}\)
采用soft-position index,允许NSP像MLM一样工作,将候选词coin的位置索引与[BLANK]对齐。
(4) Word Sense Disambiguation
在完全监督的训练场景中,作者可以在单词前后添加标记来识别要消歧的单词。
因为没有用于句子级提示学习的下游任务训练数据,所以无法通过标记来识别目标词的位置。 论文提出了一种 TwoStage Prompt 构造方法,在NSP-BERT 中使用自然语言描述来指示目标词。
- stage1:在句子 A 的末尾提示目标词。这个阶段的目的是为目标词提供足够的上下文。
- stage2:提示对句子 B 中候选词义的描述。
将两阶段提示输入语言模型,判断句子是否流畅合理。 让 $p_{i,1}^{(j)}$ ,$p_{i,2}^{(j)}$ 表示提示的第一部分和第二部分。 模型的输入是: \(X_{input}=[CLS]x_i,p_{i,1}^{(j)}[SEP]p_{i,2}^{(j)}[EOS]\)
3.3 Answering Mapping
候选-对比答案映射和样本-对比答案映射
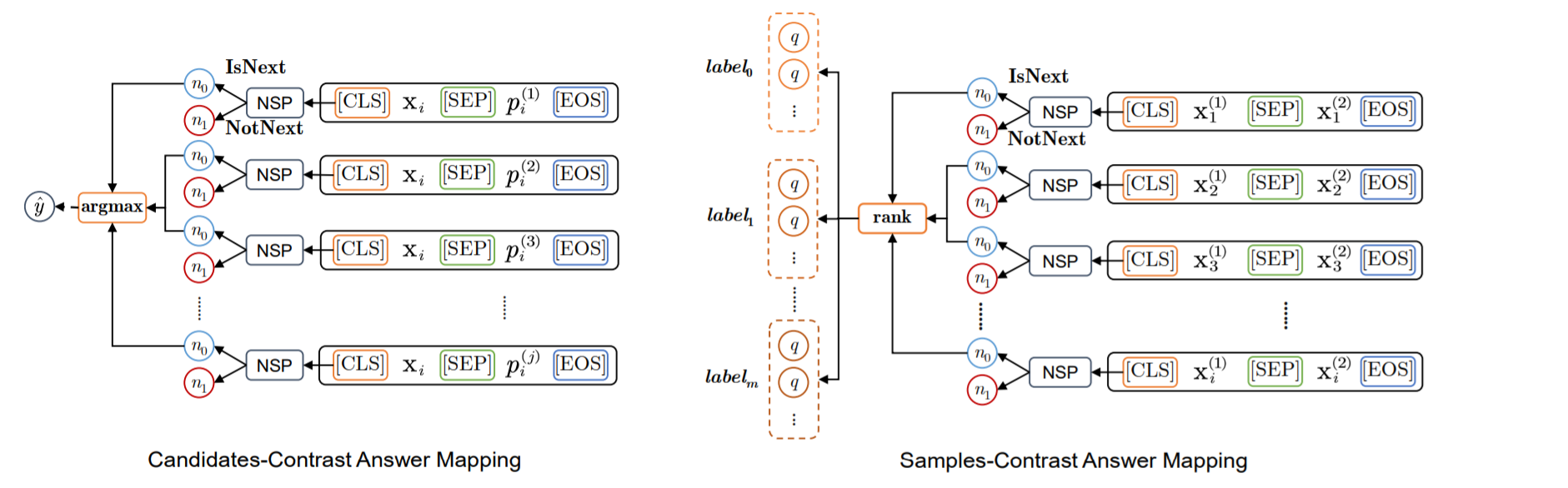
(1) Candidates-Contrast用于具有多个候选的数据集,例如候选情绪、候选主题、候选习语和候选实体。 对于上述数据集,有一个模板$p_i^{(j)}$(或$p_i$)对应标签$y_i^{(j)}$(或$y_i$)。 在条件为IsNext的情况下,将候选者中M输出的概率最高的作为最终输出答案: \(\hat{y_i}=\arg{\max_j{q(y_i^{(j)}|x_i)}}=\arg{\max_j{n=IsNext|x_i,p_i^{(j)})}}\) (2) Sample-Contrast针对没有对比候选的数据集,算法:

4 Experiment
4.1 Task and Datasets
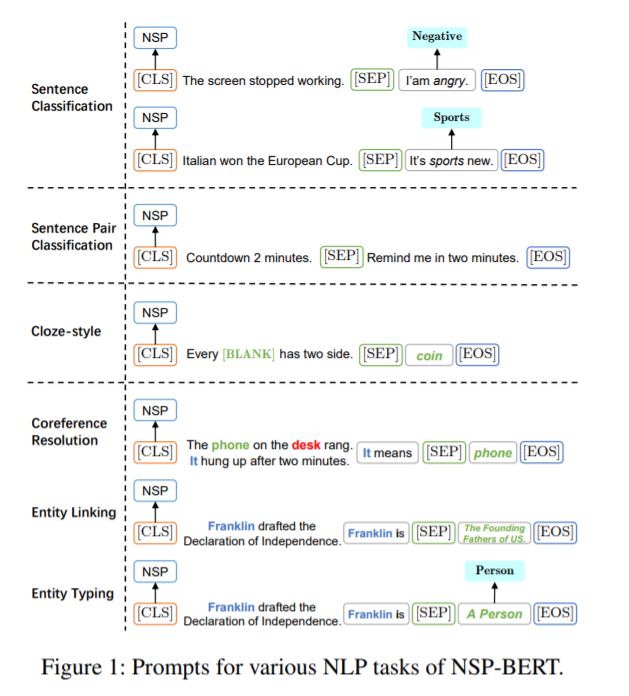
在FewCLUE上评估模型,其中包含9 个中文NLU(自然语言理解) 任务,4 个单句任务、3 个句子对任务和2 个阅读理解任务。 数据集的详细信息显示在附录中。 每个训练集中的样本数量很少,每个标签对应8或16个样本。
DuEL2.0 为了进一步验证NSPBERT在词义消歧方面的能力,增加了实体链接数据集DuEL2.0。 特别地,作者将 DuEL2.0 分为两部分。 第一部分,实体链接部分,有26586个样本。 所有样本的mention 可以映射到知识库中的单个或多个实体,每个mention 平均可以链接到5.37 个实体。 第二部分,实体类型部分,有6465个样本。 这些样本的提及在知识库中是找不到的,但是它们会被划分到它们对应的上层实体类型中。 共有 24 种上层实体类型。
4.2 Baselines
三个训练场景
-
Fine-Tuning 在FewCLUE 训练集上对预训练语言模型进行标准微调。 模型使用交叉熵损失进行微调,并使用 BERT 样式模型的隐藏向量 [CLS],$h_{[CLS]}$ 和分类层$ softmax(Wh_{[CLS]})$,其中 $W ∈ R^{M×H}$,M 是数字 的标签。
-
Few-shot 选择token-level模型 PET其优化模型 ADAPET、P-tuning和 LM -BFF。 论文还选择句子级模型 EFL。 所有的小样本模型都是在FewCLUE 的训练集上训练的。
-
Zero-Shot 在零样本场景中,有两种实现方式,一种是使用 L2R LM 的 GPT-ZERO,另一种是使用 MLM 的 PET-ZERO。
4.3 experiment settings
BERT 模型使用 RoBERTa-wwm-ext.
GPT 模型是 NEZHA-Gen 。论文采用了 UER 使用 MLM 和 NSP 训练的 vanilla BERT 。
预训练语料库是一个大型的中文混合语料库。 连同基本模型(L=12,H=768,A=12,总参数=110M),论文使用各种尺度(很小小、小和大)的UER-BERTs进行实验,以验证各种尺度模型在 NSP-BERT 上的效果 。
4.4 Main Results