FINETUNED LANGUAGE MODELS ARE ZERO-SHOT LEARNERS
微调语言模型是零样本学习器
abstract
本文探索了一种提高语言模型零样本学习能力的简单方法:指令调优——在通过指令描述的一系列任务上微调语言模型——FLAN指令调整模型。
1 Introduction
-
大规模的语言模型 (LM),例如 GPT-3,已被证明可以非常好地执行few-shot Learning。然而,他们在零样本学习方面不太成功,一个潜在的原因是,如果没有少量样本,模型很难在与预训练数据格式不相似的提示上表现良好。
-
本文探索了一种简单的方法来提高大型语言模型的零样本性能。想法来自于NLP 任务可以通过自然语言指令来描述,本文采用 137B 参数的预训练语言模型并执行指令调优——在通过自然语言指令表达的 60 多个 NLP 任务的混合上对模型进行微调。模型称为 Finetuned LANguage Net,或 FLAN。
-
本文根据 NLP 任务的任务类型将它们分组到集群中,并在对所有其他集群进行指令调整 FLAN 的同时,将每个集群用于评估。评估表明,FLAN 显着提高了基本 137B 参数模型的零样本性能。
-
消融研究发现在指令调整中增加任务集群的数量可以提高看不见的任务的性能,并且指令调整的好处只有在模型规模足够大的情况下才会出现。
-
本文实证结果强调了语言模型执行使用自然语言指令描述的任务的能力。指令调优结合了预训练-微调和提示范式的吸引人的特征,通过微调使用监督来提高语言模型响应推理时间文本交互的能力。
2 FLAN: INSTRUCTION TUNING IMPROVES ZERO-SHOT LEARNING
通过使用监督来教 LM 执行通过指令描述的任务,它将学会遵循指令,同时可以拓展到unseen tasks上。
2.1 TASKS & TEMPLATES
将 62 个在 Tensorflow Datasets 上公开可用的文本数据集(包括语言理解和语言生成任务)聚合到一个单一的混合物中,每个数据集被归类为12个任务集群之一,给定集群中的数据集属于相同任务类型。
将任务定义为由数据集给出的一组特定的输入-输出对。对于每个任务,作者手动编写十个独特的模板,使用自然语言指令描述任务,且最多包含三个模板来“扭转任务”。(e.g.对于情感分类,我们包含要求生成负面电影评论的模板)
在所有任务的混合上对预训练的语言模型进行指令调整,每个任务中的示例通过为该任务随机选择的指令模板格式化。
任务集群:
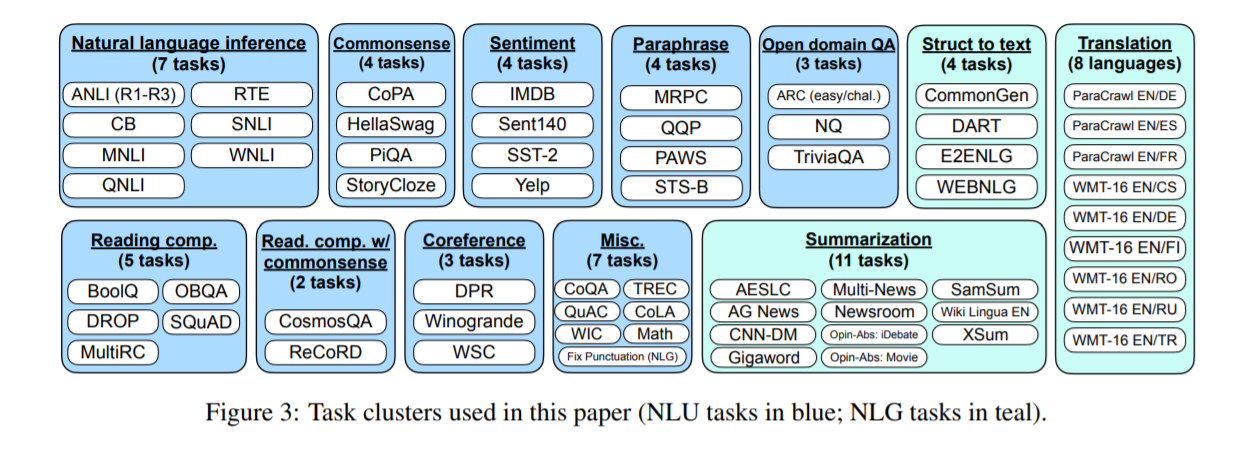
2.2 EVALUATION SPLITS
如何定义unseen task?
- 先前的工作通过禁止在训练中出现相同的数据集来对unseen task进行分类。
- 如果 $\mathcal{T}$ 是一个蕴涵任务,那么指令调整数据集中没有出现任何蕴涵任务,对来自所有其他集群的任务进行指令调整。
2.3 CLASSIFICATION WITH OPTIONS
对于分类任务,之前的任务只考虑两个输出“是/否”。本文包含一个选项后缀,将token OPTIONS 与该任务的输出类列表一起附加到分类任务的末尾, 这使模型知道在响应分类任务时需要哪些选择。
2.4 TRAINING DETAILS
(1) Model architecture and pretraining.
本次实验使用密集的从左到右、仅解码器的 137B 参数转换器语言模型,在一组 Web 文档(包括那些带有计算机代码的文档)、对话数据和维基百科上进行预训练。将预训练的模型称为Base LM。
(2) Instruction tuning procedure.
- 将每个数据集的训练示例数量限制为 30,000。
- 为了防止少训练示例的数据集被边缘化,实验遵循示例比例混合方案,最大混合率为 3000。
- 微调使用 Adafactor Optimizer, 以 3e-5 的学习率、 8,192 的批量大小进行 30,000 次梯度更新的所有模型。
- 微调过程中使用的输入和目标序列长度分别为 1024 和 256。
- 将多个训练示例组合成一个序列,使用特殊的序列结束标记将输入与目标分开。
3 RESULTS
本节在自然语言推理、阅读理解、开放域 QA、常识推理、共指解析和翻译等任务上评估 FLAN。
3.1 NATURAL LANGUAGE INFERENCE
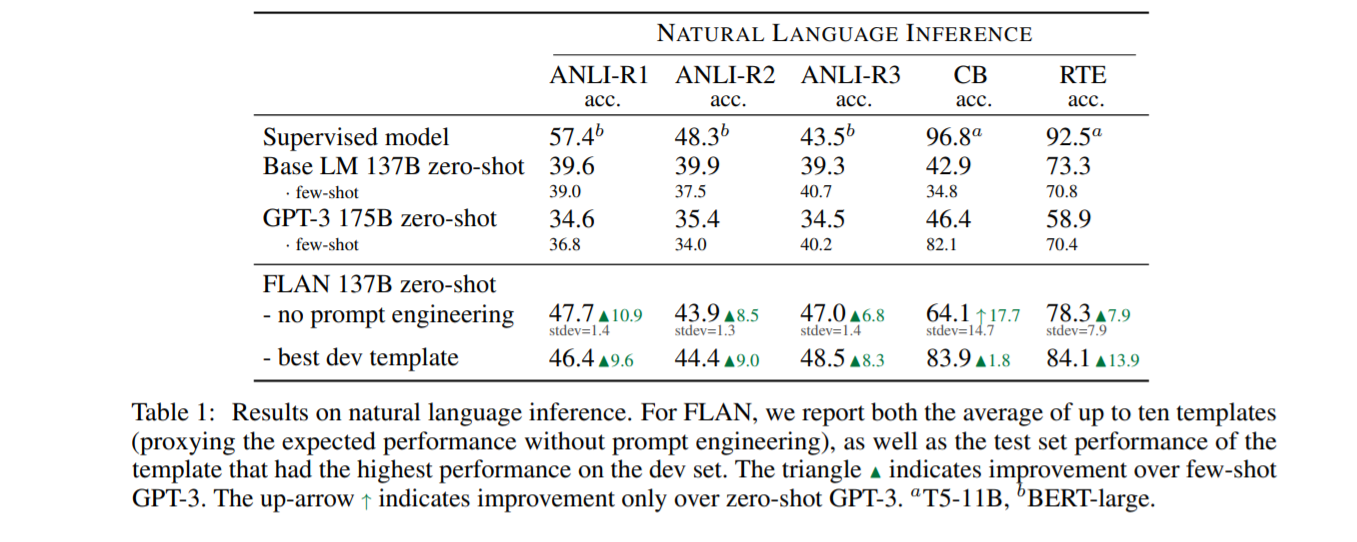
自然语言推理的结果。 对于 FLAN,我们报告了最多 10 个模板的平均值(在没有及时工程的情况下代理预期性能),以及在开发集上具有最高性能的模板的测试集性能。 三角形 N 表示对少拍 GPT-3 的改进。 向上箭头 ↑ 表示仅比零样本 GPT-3 , T5-11B,BERT-large有所改进。
3.2 READING COMPREHENSION & OPEN-DOMAIN QA
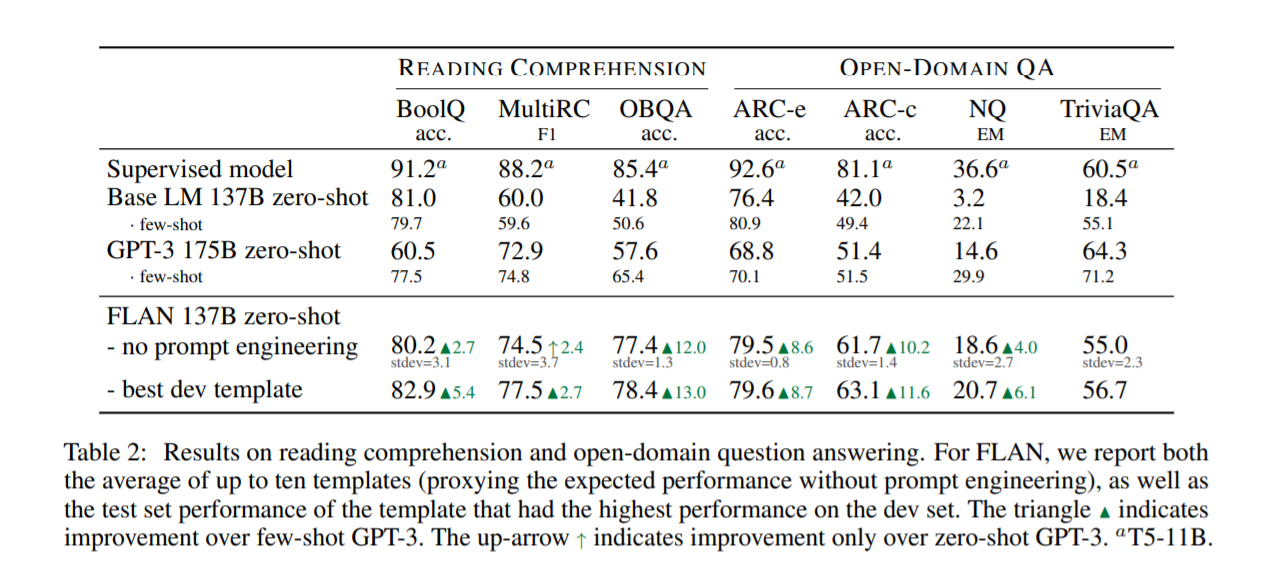
阅读理解和开放域问答的结果。 三角形 N 表示对少拍 GPT-3 的改进。 向上箭头 ↑ 表示仅比零样本T5-11B、 GPT-3 有所改进。
3.3 COMMONSENSE REASONING & COREFERENCE RESOLUTION
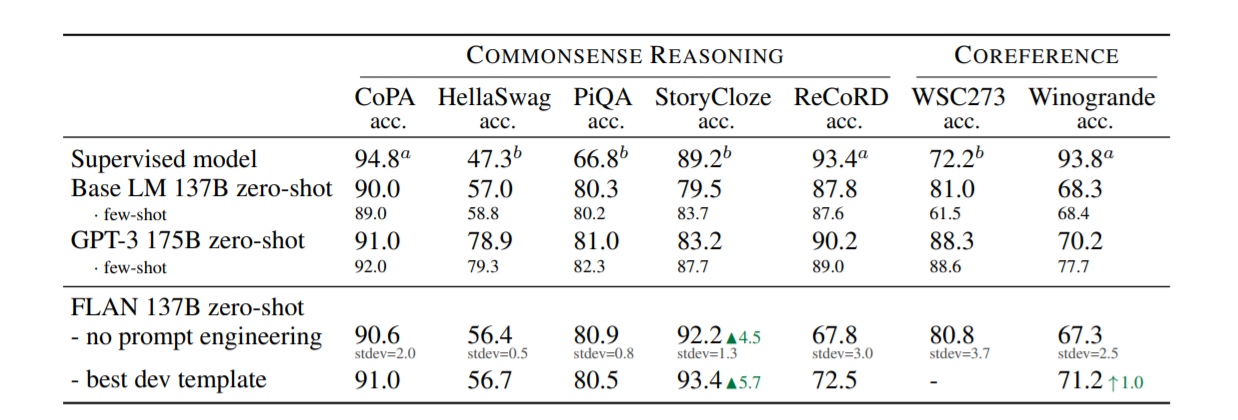
常识推理和共指解析的结果(精度为 %)。 T5-11B,bBERT-large, 三角形 N 表示对少拍 GPT-3 的改进。 向上箭头 ↑ 表示仅比零样本 GPT-3 有所改进。
3.4 TRANSLATION
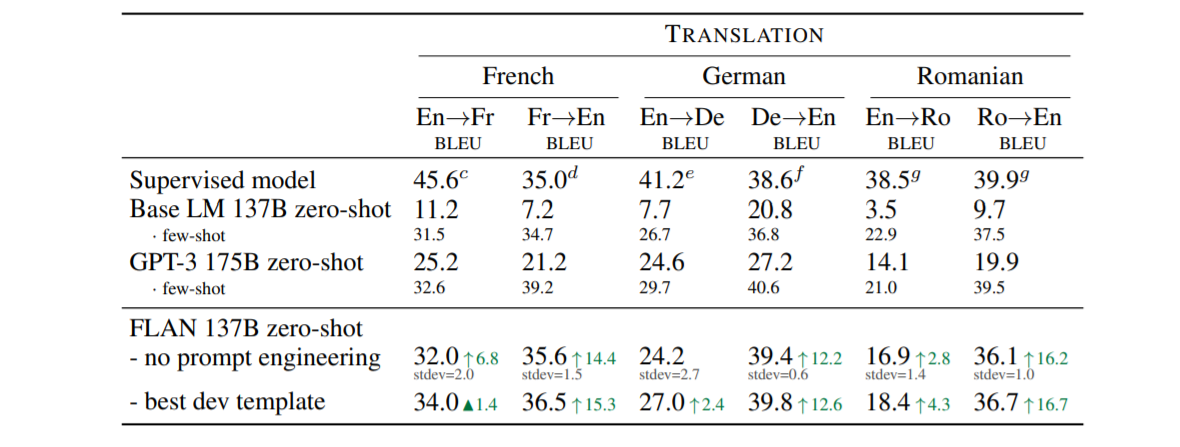
WMT’14 En/Fr 和 WMT’16 En/De 和 En/Ro 的转换结果 (BLEU)。 三角形 N 表示对少拍 GPT-3 的改进。 向上箭头 ↑ 表示仅比零样本 GPT-3 有所改进。
4 ABLATION STUDIES & FURTHER ANALYSIS
4.1 NUMBER OF INSTRUCTION TUNING CLUSTERS
在第一次消融中,本文研究了指令调优中使用的集群和任务数量对性能的影响,将 NLI、开放域 QA 和常识推理作为评估集群,并使用剩余的 7 个集群进行指令调整。
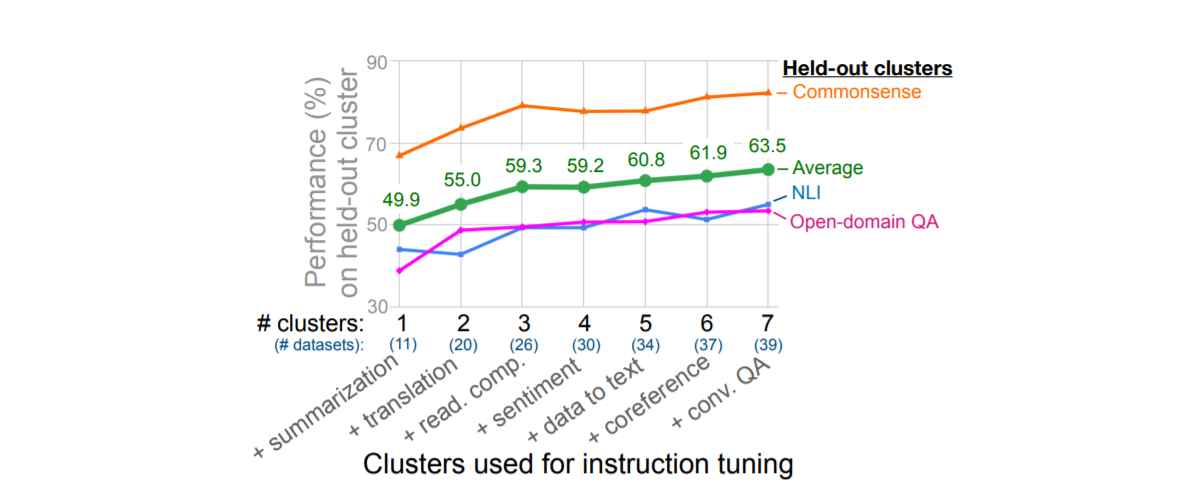
- 三个保留集群的平均性能随着我们向指令调整(情感分析集群除外)添加额外的集群和任务而提高。
- 测试的七个集群,性能似乎没有饱和,这意味着性能可能会随着指令调整中添加更多集群而进一步提高。
- 尽管从情感分析集群中看到了最小的附加值,但这种消融不允许我们得出关于哪个指令调整集群对每个评估集群贡献最大的结论。
4.2 SCALING LAWS
探讨指令调整的好处如何受模型规模的影响,评估了指令调整对大小为 422M、2B、8B、68B 和 137B 参数的模型的影响。
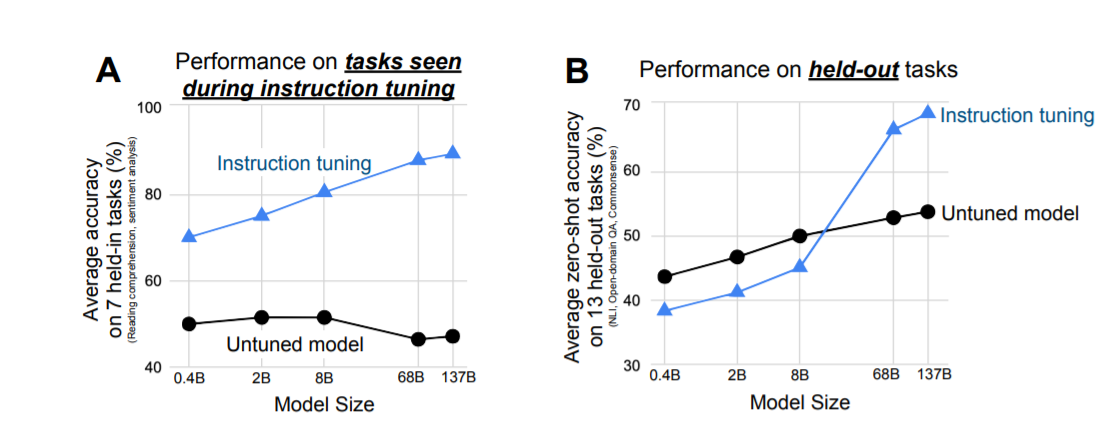
对于held-out任务:
- 对于100B 参数数量级的两个模型,指令调整显着提高了性能。
- 对于 8B 和更小的模型,指令调整实际上会损害保持任务的性能。
对这一结果的一个潜在解释可能是,对于小规模模型,学习指令调整期间使用的 40 个任务会填满整个模型容量,导致这些模型在新任务上的表现更差。对于更大规模的模型,指令调整填充了一些模型容量,但也教会了这些模型遵循指令的能力,允许它们利用剩余容量泛化到新任务。
4.3 INSTRUCTION TUNING FACILITATES PROMPT TUNING
指令调优提高了模型响应指令的能力,因此,如果 FLAN 确实更适合执行 NLP 任务,那么它也应该在使用通过提示优化的连续提示执行推理时获得更好的性能调优。
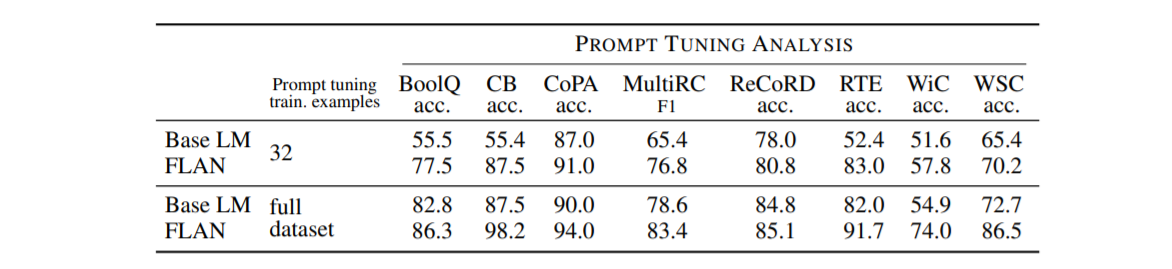
上表显示了使用全监督训练集和仅具有 32 个训练示例的低资源设置的这些快速调整实验的结果。在所有场景中,FLAN 的快速调优效果比 Base LM 更好。在很多情况下,特别是对于低资源设置,FLAN 上的即时调优甚至比 Base LM 上的即时调优提高了 10% 以上。这个结果以另一种方式举例说明了指令调整如何产生一个更适合执行 NLP 任务的检查点。
5 DISCUSSION
论文探讨了零样本提示中的一个简单问题:指令调整语言模型是否会提高其执行未知任务的能力。在 FLAN 上的实验表明,指令调优提高了针对未调优模型的性能,并在我们评估的大多数任务上超过了零样本 GPT-3。通过消融研究,发现随着指令调整中使用的任务集群数量的增加,unseen task的性能会提高,而且有趣的是,指令调整的好处只有在模型规模足够大的情况下才会出现。此外, FLAN 似乎比未修改的基本模型对即时调整的响应更好,证明了指令调整的额外好处。
本文中显示的结果为未来的研究提出了几个有希望的方向:
- 可以通过更多指令调整任务来进一步提高性能,这些任务可以以自我监督的方式生成。
- 探索多语言环境也很有价值,例如,人们可以问,在高资源语言中对监督数据进行指令调整是否会提高低资源语言中新任务的性能。
- 具有监督数据的指令调整模型也可能用于改善模型在偏见和公平方面的行为。
6 CONCLUSION
本文探讨了指令调优。我们提出了 FLAN,这是一个 137B 参数语言模型,它执行使用指令描述的 NLP 任务。通过利用微调的监督来提高语言模型响应教学提示的能力,FLAN 结合了预训练-微调和提示范式的吸引人的方面。 FLAN 的性能优于零样本和少样本 GPT-3,表明大规模模型遵循指令的潜在能力。我们希望我们的论文能够推动对零样本学习和使用标记数据改进语言模型的进一步研究。