Prompt-Learning for Fine-Grained Entity Typing
细粒度实体类型的Prompt-learning
abstract
- 通过使用完形填空式的语言提示来激发 PLM 的潜能,提示学习可以在自然语言推理、情感分类和知识探测等一系列 NLP 任务上取得可喜的成果。
- 本文研究了提示学习在全监督、少样本和零样本场景中的细粒度实体类型中的应用。
- 为了解决零样本制度,作者提出了一种自监督策略(self-supervised strategy),该策略在提示学习中进行分布级别优化,以自动汇总实体类型的信息。
- 在完全监督、少样本和零样本设置下对三个细粒度实体类型基准(最多 86 个类)进行的大量实验表明,Prompt learning方法显着优于微调基线,尤其是在训练数据不足时。
1 Introduction
近年来,预训练语言模型 (PLM) 得到了广泛的探索,并成为自然语言理解和生成的关键工具。研究人员的许多努力都致力于激发 PLM 中的特定任务知识,并将这些知识应用于下游 NLP 任务。 使用额外分类器进行微调一直是使 PLM 适应特定任务的一种典型解决方案,并在各种 NLP 任务上取得了有希望的结果。
最近在探索 PLM 知识方面的一些努力表明,通过编写一些自然语言提示,我们可以诱导 PLM 完成事实知识。 GPT-3 进一步利用提示提供的信息进行小样本学习并取得了惊人的结果。受此启发,引入了Prompt-learning。在提示学习中,下游任务被形式化为等效的完形填空式任务,并且要求 PLM 处理这些完形填空式任务而不是原始下游任务。
在这项工作中,作者全面探索了提示学习在全监督、少样本和零样本设置中的细粒度实体类型中的应用。
- 本文首先引入了一个简单的管道,在那里构建了面向实体的提示,并将细粒度的实体类型化为一个完形填空式的任务。
- 然后,为了解决在训练中不存在明确监督的零样本场景,作者在管道下开发了一种自我监督的策略,试图通过优化提示学习中成对示例的预测概率分布的相似性来自动总结实体类型。
实验使用了三个流行的基准,包括 FEW-NERD、OntoNotes 、BBN。 所有这些数据集都具有复杂的类型层次结构,包含丰富的实体类型,要求模型具有良好的实体属性检测能力。
2 Background
2.1 Problem Definition
实体类型的输入是一个数据集 $\mathcal{D} = {x_1, …, x_n}$, 有 n 个句子,每个句子 x 包含一个标记的实体mention(实体提及)m。
对于每个输入句子 x,实体类型旨在预测其标记提及 m 的实体类型 $y ∈ \mathcal{Y}$,其中 $\mathcal{Y}$ 是一组预定义的实体类型。
实体类型通常被视为上下文感知分类任务。 例如,在句子“伦敦是耶稣琼斯摇滚乐队的第五张专辑…”中,实体提及伦敦应归类为音乐而不是位置。 在 PLM 时代,使用预训练的神经语言模型(例如 BERT)作为编码器并执行模型调整以进行类型分类成为标准范式。
2.2 Vanilla Fine-tuning
对于输入序列$x={[CLS],t_1,…,m,…t_T,[SEP]}$中的每个带有实体提及$m={t_i,…,t_j}$的token $t_i$,PLM生成其上下文化的表示${h_{[CLS]},h_1,…,h_T,h_{[SEP]}}$ 。根据经验,选择token [CLS]的嵌入(embedding)作为输入输出层的最终表示:
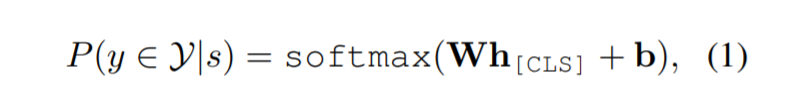
| 这里W和b是可学习参数。 W、b 和 PLM 的所有参数通过最大化目标函数$\frac{1}{n} \sum_{i=1}^{n}\log{(P(y_i | s_i))}$,其中$y_i$是$s_i$的golden type label。 |
2.3 Prompt-based Tuning
在基于提示的调优中,对于每个标签 $y ∈ \mathcal{Y}$,我们定义了一个标签词集 $\mathcal{V}_y = {w_1, . . . , w_m}$。 $\mathcal{V}_y$ 是 PLM $\mathcal{M}$ 的词汇表 $\mathcal{V}$ 的子集,即 $\mathcal{V}_y ⊆ \mathcal{V}$。 通过取每个标签对应的字典的并集,我们得到一个整体字典 $\mathcal{V}^ ∗$ 。 例如,在情感分类中,我们可以将标签 y = POSITIVE 映射到集合 $\mathcal{V}_y = {great, good, beautiful…}$。
提示学习的另一个主要组成部分是提示模板 $T(·)$,它通过在 x 的末尾添加一组附加标记将原始输入 x 修改为提示输入 T(x)。 传统上,为 PLM 添加 [MASK] 标记以预测丢失的标签词 $w ∈ \mathcal{V}^∗$ 。 因此,在提示学习中,分类问题被转换为掩码语言建模问题。
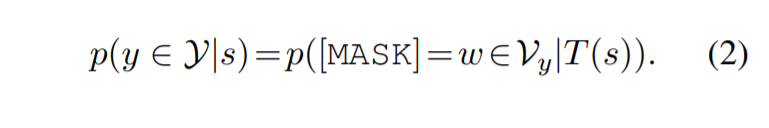
3 Prompt-learning for Entity Typing: A Naive Pipeline
本节首先介绍一个朴素但经验丰富的基线,它利用提示提取具有显式监督的实体类型,包括标签词的构建(第 3.1 节)、模板(第 3.2 节)和训练(第 3.3 节)。 这样一个简单的管道在三个基准数据集上产生了显着的结果。 然后我们提出了一种自监督的提示学习方法,可以从未标记的数据中自动学习类型信息(第 3.4 节)。
3.1 Label Words Set $\mathcal{V}^*$
对于细粒度的实体类型,数据集通常使用分层标签空间,例如 PERSON/ARTIST 和 ORGANIZATION/PARTY。在这种情况下,我们使用所有词作为该实体类型的标签词集 $\mathcal{V}^*$。 例如,y = LOCATION/CITY → v = {location, city}。
在掩码语言建模中,我们使用 $\mathcal{V}_y$ 中所有单词的置信度分数来构建特定类型 y 的最终分数。对于输入 x(映射到 T(x))及其实体类型 y(映射到 $\mathcal{V}_y = {w_1, …, w_m}$),条件概率变为
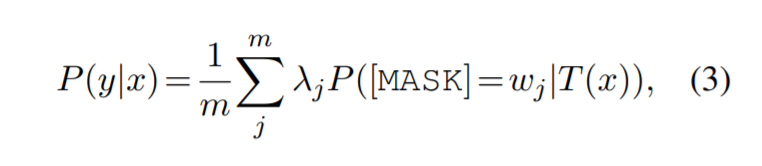
其中 $λ_i$ 是一个参数,表示当前词 $w_j ∈ \mathcal{V}_y$ 的重要性。
3.2 Templates
(1) hard-encoding templates
我们选择简单的声明性模板而不是上位词模板来避免语法错误。
在硬编码设置的模板中,我们首先复制 x 中标记的实体提及,然后添加一些链接动词和文章,然后是 [MASK] 标记。 使用标记实体提及 [Ent].

(2) soft-encoding templates
引入了一些额外的特殊标记 [P1], …, [Pl] 作为模板,其中 $l$是一个预定义的超参数。 模板以分隔符 [P] 和实体提及 [M] 的副本开头。
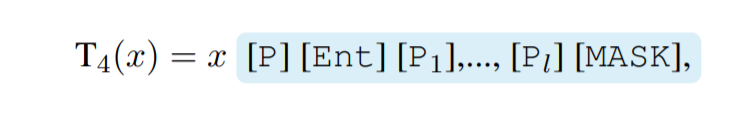
其中每个提示嵌入在训练期间随机初始化和优化。
3.3 Training and Inference
硬编码或软编码的策略提供不同的模板初始化,它们都可以通过 φ 参数化并在训练过程中与 M 一起优化。 我们使用交叉熵损失函数训练预训练模型 M(由 θ 参数化)以及附加提示嵌入:
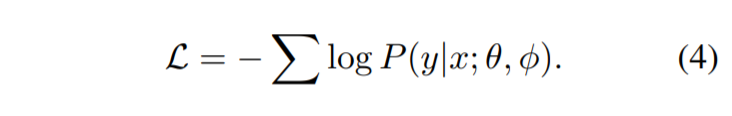
该管道可以应用于具有显式监督的实体输入任务,即使训练数据不足,即少样本场景也有效。 自然,我们考虑更极端的情况,即没有任何训练数据的场景(零样本场景)。在这种设置下,如果我们直接使用一个额外的分类器来预测标签,结果相当于随机猜测,因为分类器的参数是随机初始化的。 如果我们根据预测词使用提示来推断标签,虽然其性能明显优于猜测,但也会出现灾难性的下降。 这时候就出现了一个问题:“PLM 是否可以在没有任何明确监督的情况下预测实体类型? ”
4 Self-supervised Prompt-learning for Zero-shot Entity Typing
零样本实体类型的自监督提示学习
对于提示学习,答案是肯定的,因为在预训练阶段,实体的上下文已经暗示了相应的类型信息,这为提示学习范式提供了有利的初始化点。 例如,在带有 T3模板的输入句子中:“Steve Jobs found Apple. 在这句话中,史蒂夫乔布斯是一个[MASK]”。 在我们的观察中,PLM 预测masked位置的人的概率将显着高于位置的概率。 而如果我们合理利用这个优越的初始化点,PLMs就有可能自动汇总类型信息,最终提取出正确的实体类型。
4.1 Overview
考虑一种自监督范式,该范式优化了由相似示例预测的概率分布在投影词汇 $\mathcal{V}^*$ 上的相似性。为了在提示学习中实现这一点,需要:
- 对模型的预测范围施加限制
- 供一个未标记的数据集,其中实体mention 被标记为没有任何类型,以允许模型以自监督的方式学习诱导类型信息的过程。
输入包含一个预训练的模型 $\mathcal{M}$、一个预定义的标签模式 $\mathcal{Y}$ 和一个没有标签的数据集 $\mathcal{D} = {x_1, …, x_n}$(实体提及被标记为没有任何类型)。我们的目标是让 $\mathcal{M}$ 在 $\mathcal{D}$ 和 $\mathcal{Y}$ 上训练后能够自动进行零样本实体打字。
使用提示学习作为训练策略,我们首先从 $\mathcal{Y}$构建一个标签词集 $\mathcal{V}$,对于 \mathcal{D} 中的每个句子 x,我们用带有 [MASK] 符号的硬编码模板包装它。关键思想是使同类型实体在 $\mathcal{V}^$ 上的预测分布尽可能相似。这样,我们可以通过对正负示例进行采样来进行对比学习,同时忽略不在$\mathcal{V}^*$中的其他词对 MLM 过程中优化的影响。
4.2 Self-supervised Learning
基于一个简单的假设制定抽样策略,即不同句子中的相同实体具有相似的类型。优化单词在$\mathcal{V}^*$ 上的分布之间的相似性。这种策略不仅软化了监督,而且消除了自监督学习中其他词的影响。
本文从一个大规模的实体链接中语料库 D中随机抽取了c对正对,即共享一个相同实体mention的句子对,表示为$\hat{\mathcal{D}{pos}}$,以及c对负对,即标记了不同实体mention的两个句子,表示为$\hat{\mathcal{D}{neg}}$ 。为了避免产生假负样本,负样本进一步被包含公共实体及其类型信息的大字典限制。 仅选择字典中具有不同类型实体的句子对作为负样本。 然后用硬编码 T3(·) 包裹它们。 为了避免实体名称的过度拟合,我们使用概率为 α 的特殊符号 [Hide] 随机隐藏实体提及(在原始输入和模板中)。 根据经验,α 设置为 0.4。
由于一对示例对训练的影响应该在分布级别进行衡量,因此我们选择 Jensen-Shannon 散度作为评估两个分布相似性的指标。 因此,在一个句子对 $(x, x’ )$ 中,[MASK] 位置的预测 $h$ 和 $h’$ 的两个表示的相似性分数计算如下:
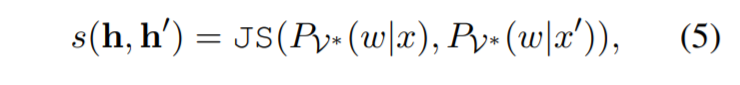
| 其中 JS 是 Jensen-Shannon 散度,$P_{V^*} (w | x)$ 和 $P_{V^*} (w | x’)$ 是通过 h 和 h’ 获得的预测标记 $w$ 对 $V^∗$ 的概率分布。 |
当为了使正对的预测相似时,目标是通过以下方式计算的:
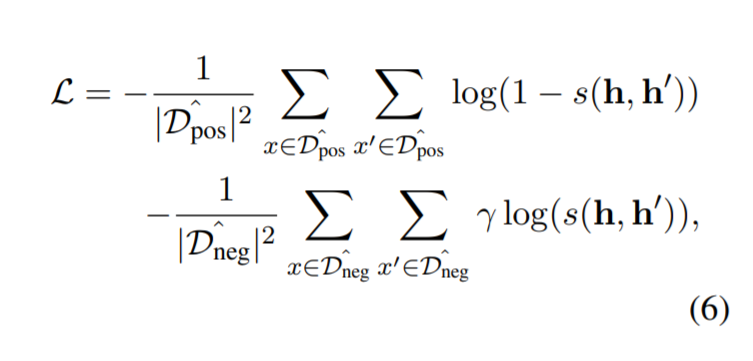
其中 γ 是惩罚项,因为假设在负对中是松散的。
5 Experiments
5.1 Datasets
FEW-NERD、OntoNotes 和 BBN。
5.2 Experimental Settings
实验在三种不同的设置下进行。
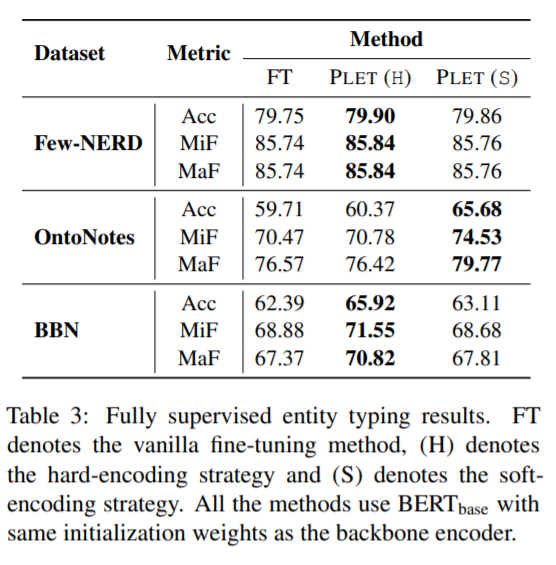
- Supervised Setting: 在完全监督的设置中,所有训练数据都用于训练阶段。FT 和 PLET 用于训练模型。 我们使用 BERT的base-cased 主干在所有三个数据集上运行实验。 硬编码和软编码都用于 PLET。
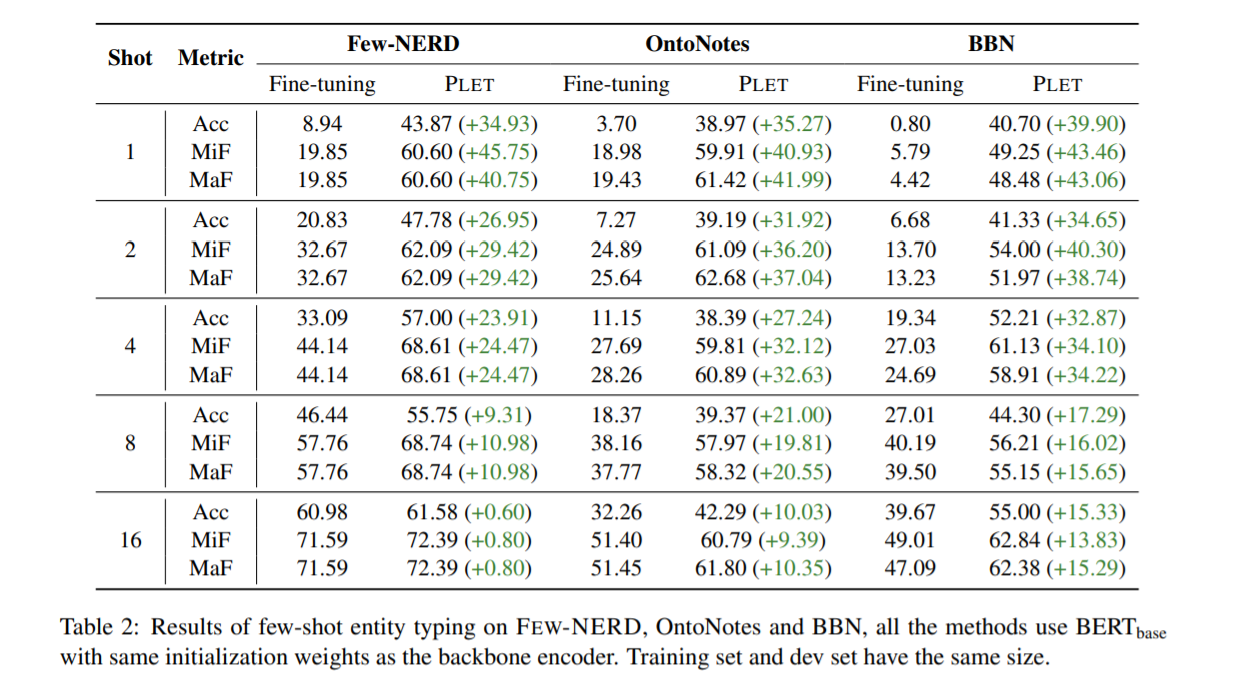
- Few-shot Setting:为每个实体类型随机抽取 1、2、4、8、16 个实例进行训练。在所有三个数据集上都应用了硬编码的 FT 和 PLET 方法。
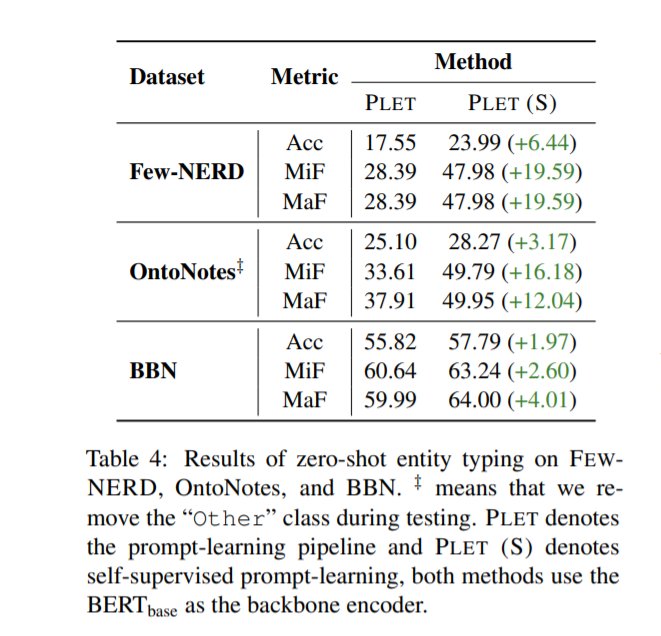
- Zero-shot Setting:仅对 PLET 和 PLET (S) 进行实验。
指标:沿用了 Ling and Weld 广泛使用的设置。
5.3 Results
- Fully Supervised Entity Typing:
- Few-shot Entity Typing:
- Zero-shot Entity Typing:
5.4 Effect of Templates
- 模板的选择对基于提示的小样本学习的性能产生了相当大的影响。
- 对于硬编码模板,描述“在这句话中”位置的短语有助于显着提高性能。
- 对于软编码模板,提示学习模型以最少的特殊标记产生了最好的结果。
6 Conclusion
- 研究了提示学习在细粒度实体类型中的应用。 本文提出了一个框架 PLET,可以在完全监督、少样本和零样本场景中处理细粒度实体类型。
- 在 PLET 中,作者首先引入了一个简单有效的提示学习管道,可用于提取具有充分监督和不充分监督的实体类型。 此外,为了处理零样本设置,作者提出了一种自监督的提示学习方法,该方法基于未标记的语料库和预定义的标签模式自动学习和总结实体类型。
- PLET 利用提示来利用分布在 PLM 中的先验知识,并且可以通过执行分布级别优化来学习预定义的类型信息而不会过度拟合。