Adapting Language Models for Zero-shot Learning by Meta-tuning on Dataset and Prompt Collections、
通过对数据集和提示集合进行元调整来适应零样本学习的语言模型
abstract
- question:大型预训练语言模型已经获得了执行零样本学习的惊人能力。例如,为了在没有任何训练示例的情况下对情感进行分类,作者可以用评论和标签描述“用户喜欢这部电影吗?”来“提示”LM,并询问下一个词是“是”还是“否”。然而,下一个词预测训练目标仍然与目标零样本学习目标不一致。
- solution:元调整 meta-tuning——通过在一组数据集上微调预先训练的语言模型来直接优化零样本学习目标。
1 Introduction
zero-shot classification
零样本分类 (ZSC) 的目标是在没有任何示例的情况下使用标签描述对文本输入进行分类。为了将 ZSC 转换为 LM 模型可能表现良好的语言建模 (LM) 任务,最近的许多工作都集中在寻找更好的提示上。
LM 训练目标是相关的,但仍然与回答提示的目标目标不一致。论文通过微调直接优化零样本分类目标来解决这个弱点。这要求:
-
1) 将不同的分类任务统一为相同的格式
-
2) 收集分类数据集和标签描述(提示)的集合以进行训练。
论文专注于二元分类任务并将它们统一为“是”/“否”QA 格式,其中输入作为上下文提供,并提供标签信息在问题中。
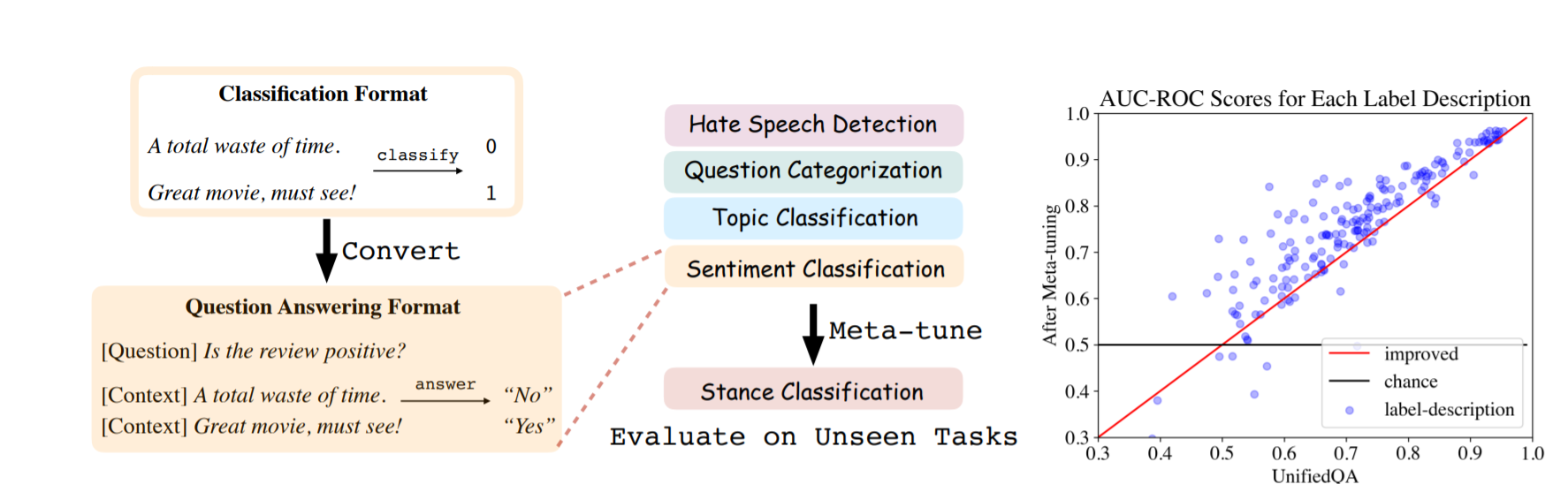
result shows:
- 大语言模型(例如 GPT-3)的零样本学习潜力,目前通过上下文提示来衡量,可能被广泛低估了;元调整可能会显着提高它们的性能。
- community-wide聚合和统一数据集的努力可以扩大零样本学习模型的培训和评估。
- 元调整方法可能会激励 LM 推理 API 的提供者收集用户的提示,从而可能导致更大规模的安全、隐私和公平问题。
contributions
- 使用专家注释的标签描述来管理分类数据集的数据集。
- 展示训练模型以执行零样本学习的简单方法。
- 确定提高性能的几个因素;特别是,较大的预训练模型更好。
2 Data
收集分类数据集,并将它们统一为“是/否”问答格式来进行二元分类,并在问题中提供标签信息。对于每个标签,注释1-3个问题。
分类数据集的目标包括但不限于情感分类、主题分类、语法判断、释义检测、定义检测、姿势分类等。体裁包括学术论文、评论、推文、帖子、消息、文章和教科书。
对相似数据集进行分组:
-
论文目标是测试模型泛化到与训练任务足够不同的任务的能力。因此,在测试时,作者不仅需要排除元调整阶段出现的相同数据集,还需要排除相似的数据集。
-
两个数据集是否执行相同的任务涉及主观意见,并没有普遍认同的定义。在一种极端情况下,大多数数据集可以算作不同的任务,因为它们具有不同的标签空间和输入分布。在另一个极端,所有数据集都可以被认为是同一个任务,因为它们都可以统一为问答格式。
-
为了应对这一挑战,论文创建了一组标签,每个标签都描述了一个数据集属性。标签集包括领域分类、文章、情感、社交媒体等。 然后定义如果两个数据集与同一组标签相关联,则它们是相似的,并禁止模型向其中一个学习并在另一个上进行测试。

3 Metrics指标
(1) Descriptive statistics描述性统计
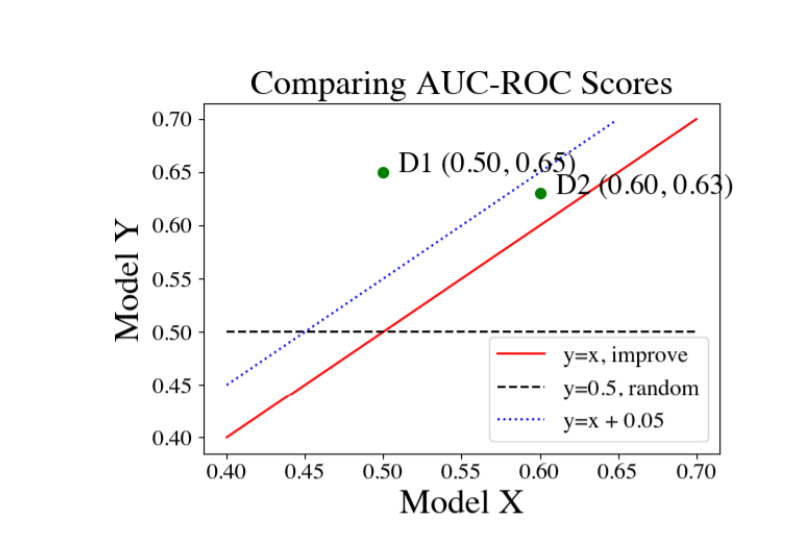
对于每个标签描述(问题),通过将“是”答案视为正类来计算 AUC-ROC 分数。在计算每个标签的 AUC-ROC 分数后,作者计算以下一组描述性统计数据比较两个模型。假设模型 Y 假设比 X 更好。将 ∆ 表示为标签描述的 AUC-ROC 从 X 到 Y 的变化,作者可以总结 ∆ 在标签描述集合中的分布情况,统计如下:

作者在此分布中对每个标签描述进行平均加权以计算上述统计量。
论文认为只有当 E[Δ] > 0 和 P[Δ > t] > P[∆ < -t] 对于所有 t ∈ {1%, 5%, 10%},在所有三种加权类型下,一个模型比另一个模型要好。
4 Model
(1) Architecture
论文以与 UnifiedQA 相同的方式格式化模型的输入,它将上下文连接到问题并在两者之间添加一个“[SEP]”标记。
然后作者将串联输入concatenated input输入到T5 编码器(Google T5)并通过对第一个解码标记的“是”/“否”概率进行归一化来产生答案分数。除非另有说明,否则论文使用 T5-Large(7.7 亿个参数)初始化模型。
对非 Seq2Seq 预训练模型进行meta-tune,例如 BERT或 RoBERTa,作者在池化输出[pooled input]/“[CLS]”标记之上添加了一个 MLP 层,以在“是”/“否”之间进行分类”。
(2) Meta-tuning
论文创建了一个训练分布,在数据集、标签描述和“是”/“否”答案之间取得平衡。
为了创建用于元调整的下一个训练数据点,从训练分割中随机均匀地选择一个数据集(u.a.r.);然后选择一个标签描述(问题)u.a.r.并以 50% 的概率选择答案为“是”/“否”的文本输入。
为了防止过度拟合,不对标签描述和文本输入的任何组合进行两次训练。对模型进行了 5000 步元调整并使用batch size为 32。
为了评估每个数据集上的 ZSC 性能,作者将一组类似的数据集作为评估集省略,并在其余数据集上进行训练。
5 Results
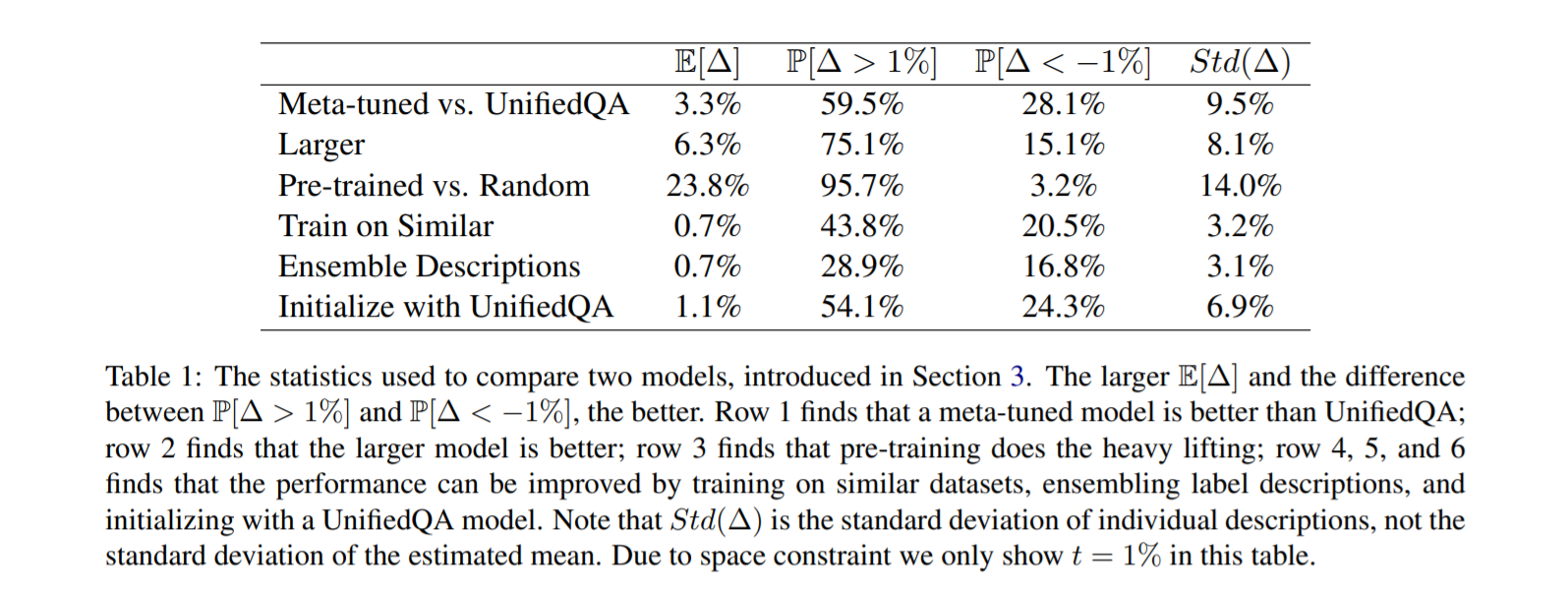
5.1 Hypotheses and Conclusions假设和结论
-
元调整模型在零样本分类中优于一般问答模型。
- 较大的预训练模型更好。
- 预训练完成繁重的工作。
- 性能可以通过对类似数据集进行训练、使用 QA 模型进行初始化或集成标签描述来提高。
- 提前停止对性能至关重要。
5.2 Robustness Checks
将 60M 参数模型与 220M 参数模型进行了比较,发现后者要好得多。然而,一个问题是作者的模型是用 T5 初始化的,它在开放网络上训练并且可能已经看到了作者收集的数据集。因此,更大的模型可能更好,因为它们更擅长记忆。
6 Discussion and Future Directions
(1) Main takeways
本文构建了一个分类数据集,以通过元调整使语言模型适应零样本分类(ZSC)。适应模型优于通用问答模型和基于自然语言推理的现有技术。作者预测元调整在更大的模型上会更有效,而当前零样本学习的工程上限可能被广泛低估。
(2) Aggregating and unifying datasets
研究难点:
- 寻找新的NLP任务
- 为每个数据集手动编写程序来转换为所需的格式
- 很难仅仅通过数据集的来源来判断数据集的质量,有时需要手动检查数据集。
(3) Meta-tuning as a probe
测量 GPT-3 等大型语言模型的智力或少样本学习能力兴趣越来越大。然而,由于这些模型不适用于回答这些提示,作者怀疑其执行小样本学习的知识和真正潜力比报告的要高得多。由于预训练完成了繁重的工作,元调整不太可能为模型提供额外的 ZSC 能力,因此我们可能首先使用元调整作为探针,使它们在测量其性能之前适应回答提示。
(4) Beyond Shallow Correlations
一种可能性是该模型仅从元调整中学习浅层统计相关性,而不是“更复杂的推理技巧”。例如,“令人兴奋”一词可能更多地出现在正面评论中。这不太可能,因为较大的模型始终比较小的或随机初始化的模型更好。为了解释这种性能差距,较大的模型必须学会在元调整期间使用更复杂的特征。
(5) Relation to Meta/Multitask-Learning
模型不会从任何目标任务示例中学习。此处的meta”并不意味着“meta-learning”,而是反映了模型从任务的元数据集中学习的事实。
(6) Annotating Prompts
标注匹配目标用户分布的提示将是一个重要的研究方向。
此外,更短、更自然的描述有时无法准确捕捉标签的语义。例如,“医疗”标签的描述是“人们需要医疗援助”;或者,它可以更长但更准确:“人们需要支持医生和其他卫生专业人员工作的联合卫生专业人员”。如何在没有专家的努力下可扩展地生成更准确和详细的标签描述将是另一个未来方向。
(7) Optimizing Prompts
本文的工作是对最近优化提示以实现更高准确性的工作的补充。即使元调谐模型专门用于回答提示,它对不同提示的反应仍然可能非常不同。例如,在立场分类数据集中,为同一个标签标注了两个标签描述(提示):“这篇文章支持无神论吗?”和“这篇文章反对有宗教信仰吗?”。它们具有相似的含义,但前者的准确性比后者低得多。作者推测这是因为该模型无法为“无神论”等抽象概念提供依据。